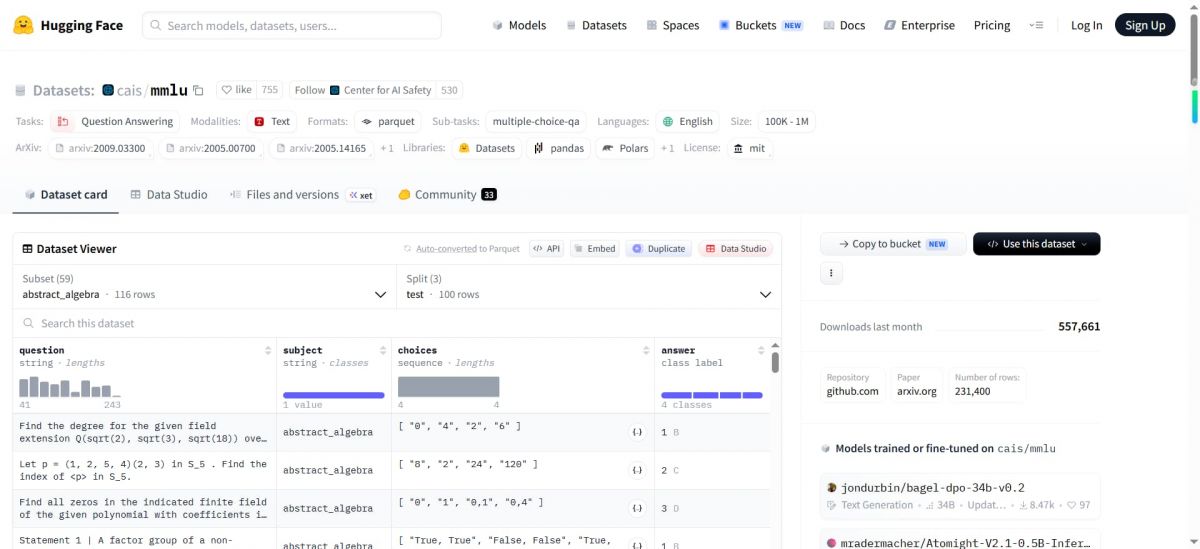
MMLU:大语言模型多任务语言理解能力的国际权威评测基准
MMLU(Massive Multitask Language Understanding)是由加州大学伯克利分校等机构联合发布的大规模多任务语言理解评测数据集,涵盖57个学科领域,包括人文科学、社会科学、自然科学、工程技术以及医学、法律、数学等专业领域,题目难度覆盖从初等知识到高阶专业知识。测试集包含约14,000道四选一选择题,用于评估大语言模型在零样本和少样本场景下的知识储备与推理能力,是目前全球引用率最高的大模型评测基准之一。
在大型语言模型能力评估领域,有一个名字几乎出现在每一篇大模型论文的评测章节中,它就是MMLU。全称为Massive Multitask Language Understanding,即“大规模多任务语言理解”,这套评测基准由加州大学伯克利分校等顶尖机构于2020年推出,至今仍是全球AI社区引用率最高、认可度最广的大模型知识理解能力测试集。无论是最新的GPT系列、Claude、Gemini,还是Llama、通义千问等开源模型,MMLU得分都是衡量其综合实力的核心指标之一。
MMLU最核心的优势在于其广泛的学科覆盖和专业的题目质量。整个数据集涵盖了57个不同的学科领域,从基础的高中数学、物理、化学、生物、历史、地理,到进阶的大学阶段的计算机科学、经济学、哲学、心理学,再到高度专业化的医学(如临床知识、解剖学、遗传学)、法律(如国际法、公司法、知识产权法)、工程学(如电气工程、机械工程)等。这种跨学科、跨难度的设计使得MMLU能够全面测试一个模型的知识广度和深度,而不仅仅是某一个特定领域的熟练程度。一个模型在MMLU上的得分,大致可以反映其在人类知识体系中的综合储备水平。
从数据规模来看,MMLU提供了约14,000道精心设计的选择题,全部为四选一格式,每题仅有一个正确答案。这些题目并非简单的记忆类问题,而是需要模型具备理解、推理和知识迁移的能力。例如,一道涉及物理学的题目可能需要模型理解力学原理后进行计算推理;一道医学题目可能需要模型结合病理知识和临床表现做出诊断判断。为了真实反映模型在实际使用场景中的表现,MMLU设计了零样本和少样本两种评测模式。零样本模式直接给模型出题,考验其预训练阶段积累的知识;少样本模式则提供少量示例,考验模型从示例中学习并泛化的能力。目前,主流模型通常会在5样本(5-shot)设置下进行评测,这也是论文中最常引用的分数基准。
MMLU在技术层面还有一个值得关注的设计亮点,即题目难度的区分度和排名机制的严谨性。全球各大AI公司都会将自己的模型提交到MMLU官方榜单进行对比,形成了一个透明的竞技场。截至目前,顶级模型在该基准上的得分已经超过90%,例如GPT-4在某些版本中达到了86-90%的水平,而Claude 3 Opus、Gemini Ultra等模型也稳定在85-90%区间。这些分数反映出一个重要趋势:大语言模型在人类知识理解层面已经接近甚至超越了人类专家的平均水平(人类基线约为89.8%)。然而,MMLU的设计者也指出,高分并不意味着模型真正“理解”了这些知识,因为模型可能通过训练数据中的记忆来回答问题,这也是该基准被持续改进的原因之一。
MMLU的开源属性使其成为了AI社区的公共基础设施。任何研究者都可以从Hugging Face等平台下载该数据集,用于评估自己开发的模型,并与社区公开的分数进行横向对比。这使得MMLU成为了连接学术界和工业界的“通用语言”——无论是在论文中报告新模型的性能,还是在产品选型中对比不同模型的优劣,MMLU得分都是一个绕不开的参考标准。当然,随着模型能力的不断提升,社区也意识到了MMLU的局限性,比如部分题目可能已经出现在模型的训练数据中,导致分数存在一定的“污染”风险。针对这一问题,MMLU团队及其衍生项目(如MMMU、MMLU-Pro等)正在持续推出更具挑战性的升级版本。但无论如何,作为大模型评测领域的“奠基之作”,MMLU的地位和价值在可预见的未来仍将不可撼动。
如果如果你想对比更多同类型工具,也可以前往AI模型评测查看完整列表。